
大概是和 oom 杠上了 - -!
今天遇到一个比较奇怪的问题,在平台自己的监控数据查看某个 Pod 的时候发现只用了 30m, 并且 limit 设置的是 100m, 但是发现 OOM 了。
通过使用命令 kubectl top pod <podName> 获取到的内存占用也是 30m,所以初步怀疑是系统的 OOM 造成的。
登陆到 Pod 所在节点后,使用 dmesg -T | grep Kill 命令查看了下日志,找到 Pod 中记录 OOM 的时间点,找到对应的日志,如下:
[Mon Dec 30 14:02:31 2019] Memory cgroup out of memory: Kill process 3689454 (reference) score 1215 or sacrifice child
[Mon Dec 30 14:02:31 2019] Killed process 3689409 (reference), UID 0, total-vm:707908kB, anon-rss:19312kB, file-rss:5520kB, shmem-rss:0kB
显示的是被 cgroup 的限制给杀掉的。这里补充下,OOM 有两个原因:
- 操作系统的 OOM
- cgroup 的 OOM, 这种情况是由于
Pod中的Container设置的limit, 当使用资源超过limit的时候会触发 OOM.
这里又去 Prometheus 查询了下数据,
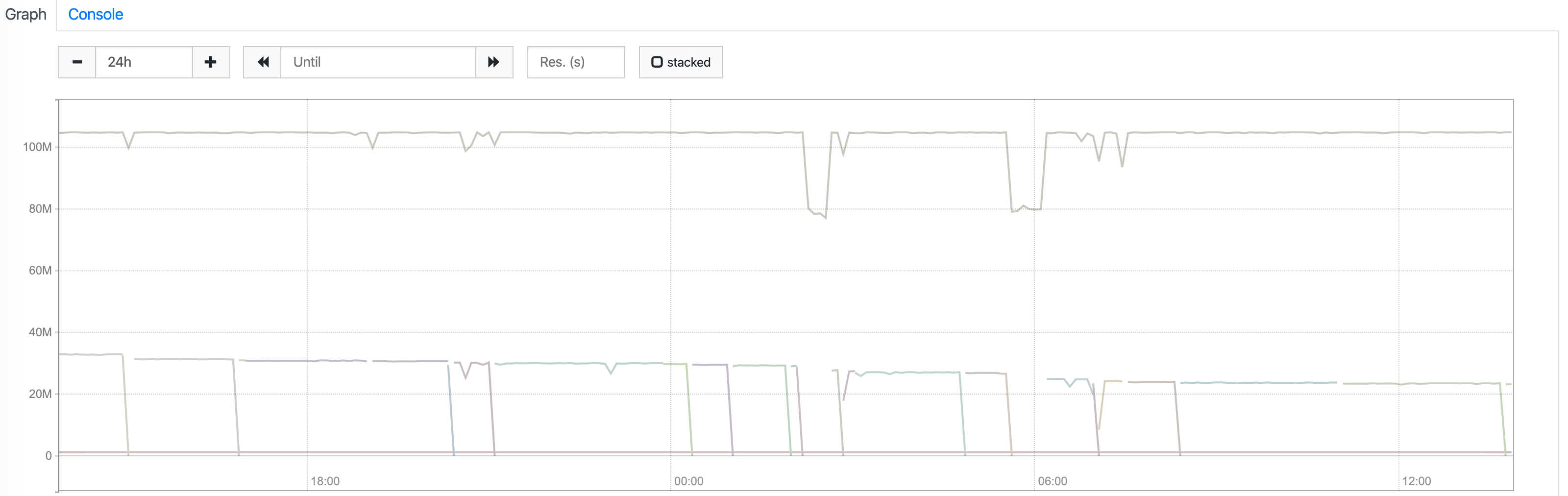 发现有好几条数据,最上面的那条是
发现有好几条数据,最上面的那条是 Pod 的 container_memory_usage_bytes, 确实达到了 100M, 而下面的两条数据分别是这个 Pod 下 Container 的数据,按理来说下面数据的加起来等于 Pod 的数据才对,这里怀疑是不是 Prometheus 出错了,所以准备去查看系统的 cgroup 信息。
登陆到对应节点的主机。在目录 /sys/fs/cgroup/memory/kubepods/ 下会有几个文件夹:besteffort、burstable 和 guaranteed,查看下 Pod 的 QosClass 进入对应的目录,然后会看到很多类似于 pod051f90c3-2ac0-11ea-a9b5-525400003709 这样的目录,这里的拼写规则是 pod + pod.uid 来的,所以很容易就可以进入指定 Pod 的目录下,大概会看到一下!

这里的 memory.max_usage_in_bytes 保存的就是当前 Pod 的使用情况,然后再分别进入两个容器目录下查看了对应的内存和 Prometheus 看到基本一致。同事告诉我这是 cgroup 的一个 bug,在新版本的内核中已经修复了。去 github 上找了下有个类似的 issue, 里面有人尝试 echo 1 > /sys/fs/cgroup/memory/docker/memory.force_empty 去解决问题, 但是今天试的时候发现报错 -bash: echo: write error: Device or resource busy,目前的解决办法是杀掉这个 Pod 然后让 k8s 起一个新的。
记录下当前的内核版本
Linux kube-node-2 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
顺便记录一个链接
https://ops.tips/blog/why-top-inside-container-wrong-memory/